
How to Organize Data
If and when your data sharing plan request is approved, we will work with you to set up a repository for your data, known as a project, in Synapse. We will create a folder structure based on community standards for contributors to use.
This page explains best practices for organizing data and other materials within your NF project. Following this structure will make annotation and other data management easier both for you and NF-OSI staff.
Project Folders Overview
Your Synapse project will usually be set up with these top-level folders:
Raw Data or Data - contains subfolders organized by expected datasets.
Milestone Reports or Reporting - contains generated reports for project; your program officers may also upload reports here.
Data Sharing Plan - contains versioned copies of your Data Sharing Plan.
Analysis - figures or other outputs not considered “raw data”.
Note: older or independent projects (not sponsored by one of our funders) may not have this exact top-level scheme.
This structure determines how easily others can find and understand your contributions, how easily you can annotate data, and how governance can be applied.
You can create other top-level folders to house materials that fall outside the scope of the pre-generated folders, and these will be ignored.
Raw Data or Data
The Raw Data or Data folder will have folders for datasets based on your data sharing plan. This format must be followed in order for your data to be detected with our data curation application.
Typical structure
Raw Data
├── Imaging
├── img1.tiff
├── img2.tiff
├── manifest.csv
├── Cognitive Assessments
├── a_visit.xlsx
├── b_visit.xlsx
├── manifest.csv
├── RNA-seq
├── abc.fq.gz
├── def.fq.gz
└── manifest.csvWhen created, these dataset folders are automatically tagged with the special key-value contentType=dataset.
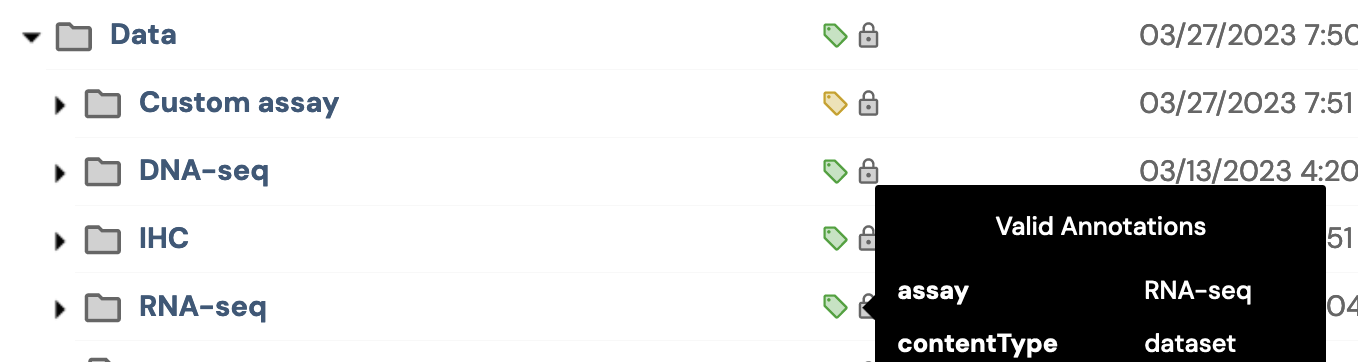
If the Data Sharing Plan changes, you will need to add or delete some of these folders. Currently, wou will need to add the contentType key-value pair yourself in order for the dataset to be detected in the curation application.
Files should be in a folder under Raw Data and not directly under Raw Data, even if there is only one type of dataset/files. For raw data types and formatting recommendations, see How to Format Your Data.
Finer organization
For each data type, it is possible to group data with batches or certain other factors. For example, the RNA-seq data folder may have subfolders “batch 1” and “batch 2” that were produced at different times during the project.
You may do something similar with cohort, having subfolders for MRI data with “French” vs “US” patient groups, which may be especially helpful later on if different consents or geography-specific legal requirements apply to that dataset.
Milestone Reports or Reporting
This folder should house the summary reports that link data files to specific award milestones. Unlike with Raw Data or Data folders, files within the Milestone Reports or Reporting folder usually won’t need further partitioning. This folder is most relevant to funders as opposed to data re-users. Sometimes, reports housed in this folder are generated by the NF data coordination team.
Analysis
This folder can house the protocols, code, and derived results that comprise an analysis performed on raw data.
In addition to the Analysis folder, each project has its own Docker Registry to store and distribute analysis code. To make analysis code more reproducible, Docker images include both the code and the software dependencies and configurations needed to run the analysis. See Synapse Docker Registry for more information and instructions.