
About
The NF Data Portal is a public data repository that stores and shares data generated by multiple collaborative research programs focused on neurofibromatosis (NF) diseases (neurofibromatosis type 1, NF2-related-schwannomatosis, and other forms of schwannomatosis). Collaborators and Sage Bionetworks support the portal, open science, and the NF research community through the effort collectively called the NF Open Science Initiative (NF-OSI). Children’s Tumor Foundation (CTF) and the Neurofibromatosis Therapeutic Acceleration Program (NTAP) participation dates back to 2014. More recent participants include the Gilbert Family Foundation (GFF), the Developmental and Hyperactive Ras Tumor SPORE (DHART-SPORE), and the CDMRP Neurofibromatosis Research Program (NFRP). Importantly, anyone in the NF research community can join the NF-OSI. Learn more about joining the NF-OSI here.
Because NF diseases are relatively rare, samples and data generated in this area are precious. This is why open science principles are so valuable—data sharing and collaboration maximizes the value and impact of research, and the NF Data Portal exists to support this joint effort. Read more about open science and data sharing here. See our past Hackathon projects to see examples of re-use.
Some studies are funded in conjunction with one another—such a group of funded projects is called an initiative on the portal. Funded studies produce data files, metadata and annotations, publications, and biological tools like cell lines, mouse models, and plasmids. Study products, such as multiple data files, may be bundled into a dataset, or explored and analyzed with computational tools developed by the community.
Learn about the organizational structure and contents of the portal here.
Collaborators and Funding

The NF Data Portal was built and is maintained thanks to generous support from:
The Children’s Tumor Foundation (CTF-2018-04-002, CTF-2021-04-006)
Neurofibromatosis Therapeutic Acceleration Program
Gilbert Family Foundation
Leona M. & Harry B. Helmsley Charitable Trust (2018PG-HPL007)
Our Data Lifecycle
The studies featured on the NF Data Portal embrace open science principles and operate under a regulated data lifecycle:
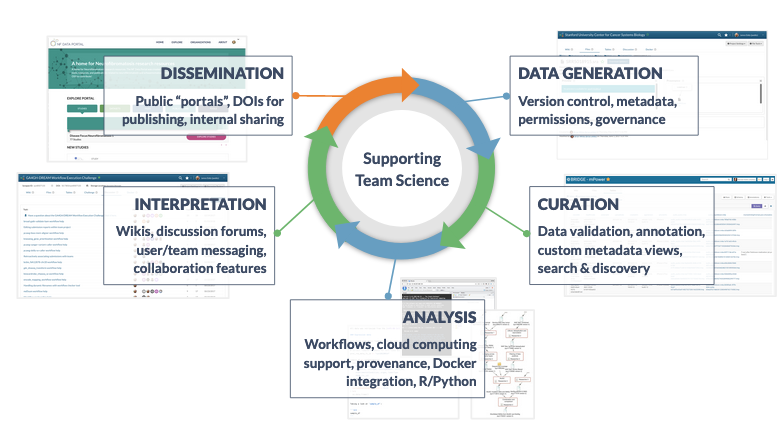
As a user of the portal, you can engage with as many of these stages as fits your needs. Each stage of the data lifecycle manifests on the portal in different ways.
During the data generation phase, data are uploaded to the data storage platform, Synapse. During this phase, the data are typically not available for download on the portal, but some information is exposed, such as study title, study description, and metadata.
Data curation mostly occurs behind the scenes of the portal on our data storage platform, Synapse, but this stage enables data discovery, powering search and exploration on the portal.
Data analysis surfaces on the portal through biological and computational tools and is boosted through information available on the portal such as metadata and provenance.
Data interpretation is enabled through various Synapse features, including wikis and discussion forums, but can also be explored on the portal via published data, associated publications, and tools.
Data dissemination includes the NF Data Portal, journal publications, and other means of data distribution.
For an in-depth review of the NF Data Portal’s community engagement and structure, please see our article in Scientific Data.
NF Data Portal ↔︎ Synapse
At this point, you know what the NF Data Portal is, and have likely come across the term Synapse - but how do they fit together? Let’s break this down:
Sage Bionetworks | Sage Bionetworks (also referred to as Sage) is a non-profit organization based out of Seattle, Washington. Sage is dedicated to promoting and advancing open science, as well as engaging patients in the research process. Sage acts as the Data Coordinating Center (DCC) for several different portals, including the NF Data Portal. The scientists, developers, and designers that built the tools you’re using are all employed by Sage. You can learn more about Sage Bionetworks and its initiatives here. |
Synapse | In line with advocating for open science, Sage developed a software platform called Synapse. This platform is what allows for collaborative data curation and analysis, computational modelling, and more. It allows users to upload, store, analyze, and track data in a private space, before releasing it to the public-facing NF Data Portal. Think of Synapse as the back-end for all the data to live in. |
NF Data Portal | If Synapse is the back-end for data, the NF Data Portal is the front. It’s essentially the user interface (UI) or entry point for you to view data and other shared content. Data gets uploaded into Synapse and becomes searchable and accessible in the portal. |
NF Data Standards
Data standards underpin data sharing and make it possible to successfully explore, access, analyze, and reuse data. Data standards involve:
metadata (information about data)
schemas (collections of data attributes/keys, descriptions, and valid values—in tabular data, attributes are usually represented as column headers)
ontology (the terminology, or values, used in the data)
any other imposed rules that enable data sharing
Where possible, Sage Bionetworks models its data standards on established global standards to promote interoperability across platforms, in support of FAIR data sharing. When these components work together, data standards allow users to find data, and ensure all information is present for successful reuse and analysis.
The majority of data available in the NF Data Portal is sequencing data, such as RNA sequencing and whole exome sequencing, though we also have a variety of imaging assays and other data. We derive most of our data standards and collection of standardized keys and values from vetted sources such as the National Cancer Institute’s Genomic Data Commons (NCI’s GDC) and NCI Thesaurus. If you already use or consult those standards, the following terminology may be familiar to you.
Metadata Standards
For the most part, we collect scientific metadata (also referred to as annotations) that documents information about the experimental assay—for example, with sequencing data, information such as:
type of assay (
assay)platform used (
platform)library preparation type (
libraryPrep)read (
readLength,readPairOrientation,readStrandOrigin).
However, we also collect information related to the data project, such as:
general information about the data (
filename,fileFormat,resourceType,dataType,dataSubtype)
Investigators provide metadata by filling in manifests (spreadsheets) using the NF Data Curator App. For more information on annotating data, see How to Annotate Data.
To allow for data standards, we control the terminology used for values through (meta)data dictionaries and other tools. Using controlled vocabularies and other data standards allows you to find what you’re looking for on the portal, so that you don’t have to search through multiple terms for the same thing. For example, instead of ribonucleic acid sequencing, or RNA-Seq, we use the value RNA-seq.
You can find our full data dictionary at our open-source GitHub repository.
Quarterly Newsletter
Looking for NF Portal and NF-OSI news? Subscribe to the NF-OSI newsletter here.
Help & Feedback
If you have questions, suggestions or other feedback about the NF Data Portal, please contact us at nf-osi@sagebionetworks.org.